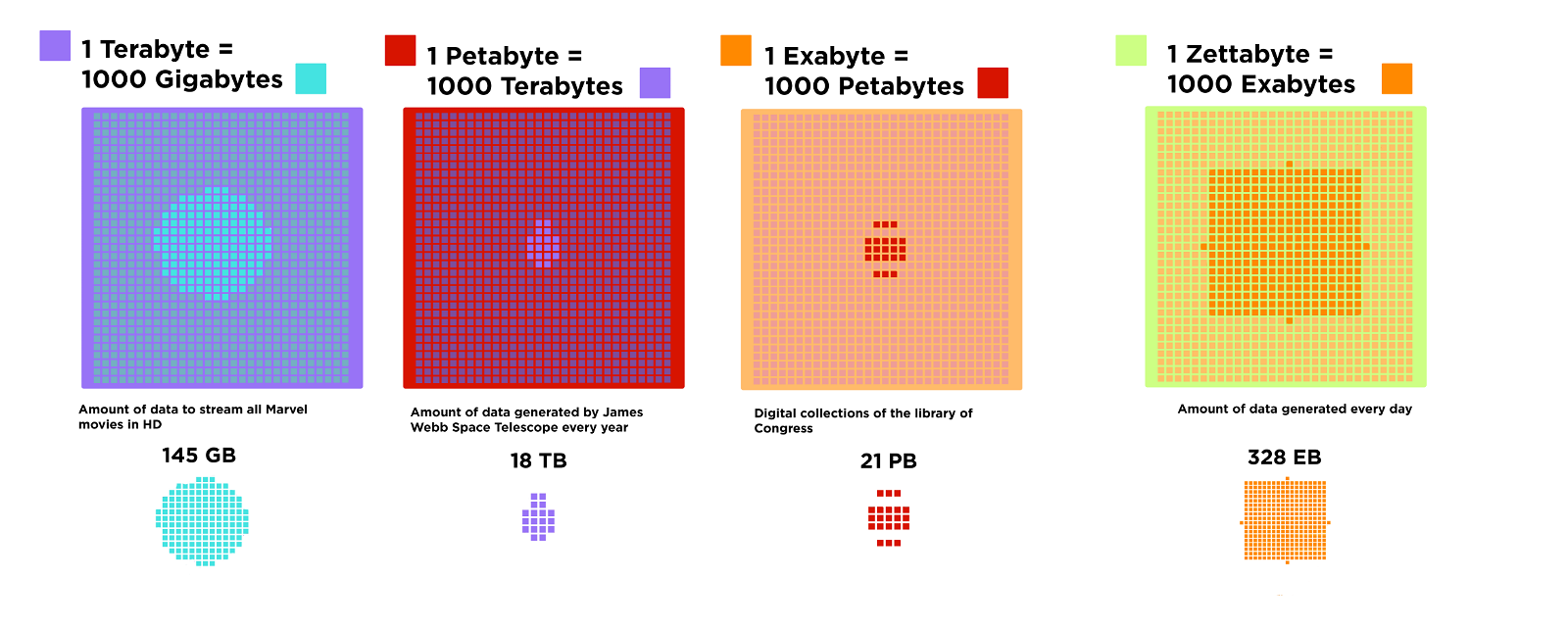
Machine learning algorithms—What's in the black box?
Artificial intelligence and machine learning help us make sense of big data. They can find patterns, analyze data, and predict what might happen next. It can seem like magic: data goes in, and answers come out. But behind those “magic” results are many rounds of training and refining.
Machine learning is how computer algorithms learn to find meaningful information in data. Machine learning algorithms are sets of programmed instructions. These instructions tell the algorithm how to update its procedures depending on the data it encounters.
Machine learning developers train algorithms on an existing dataset. If the algorithm is learning to read x-rays, for example, developers will give it lots and lots of existing x-ray images.
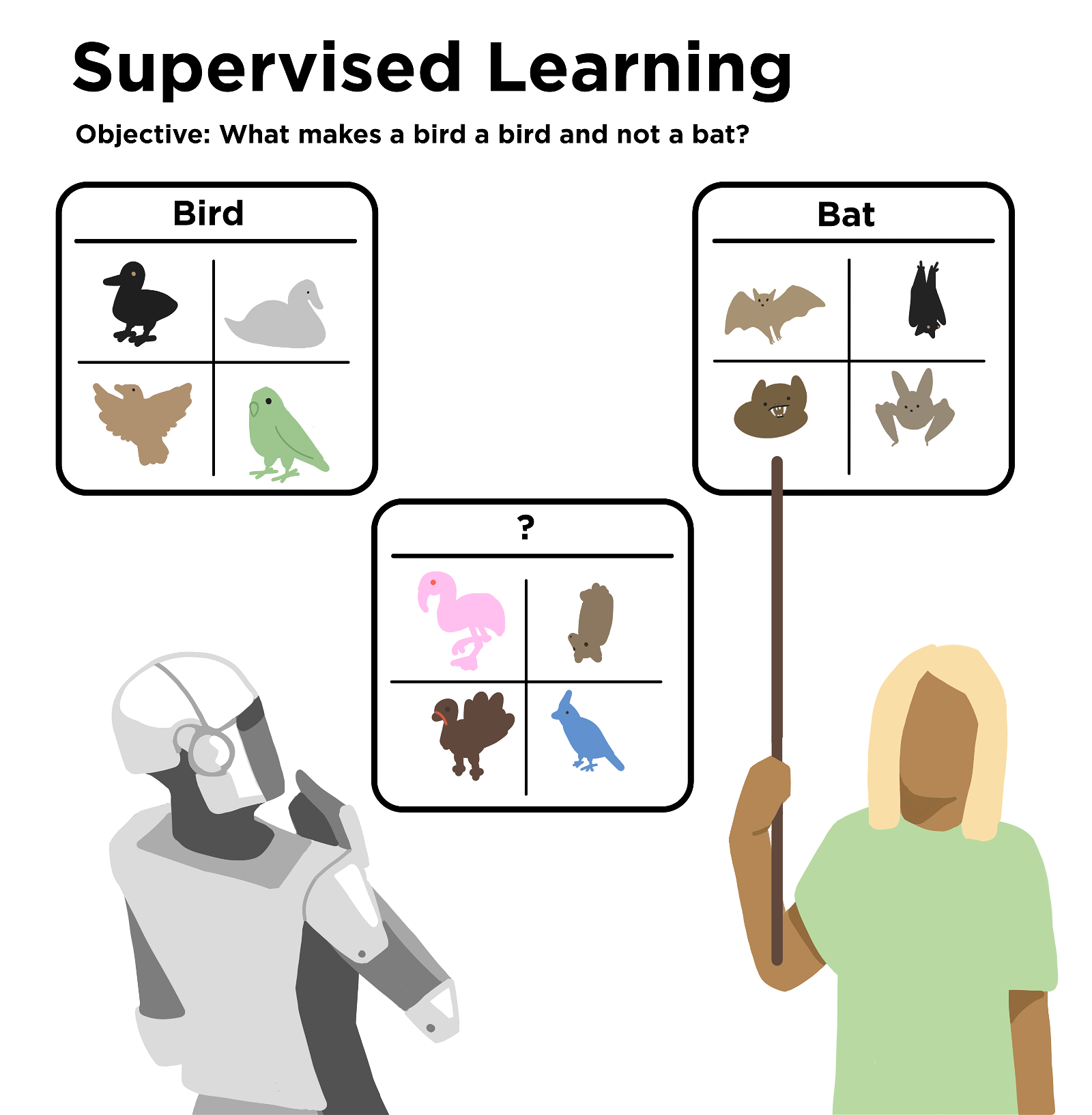
In supervised learning, the developers give the algorithm labels to help it know what to look for. For example: whether or not an x-ray shows a broken wrist. The labels help the algorithm learn the difference. After “training,” the developers would then give the algorithm a new set of unlabeled images. The developers want to see how well it does. This training and validation process continues until the algorithm produces good enough results.
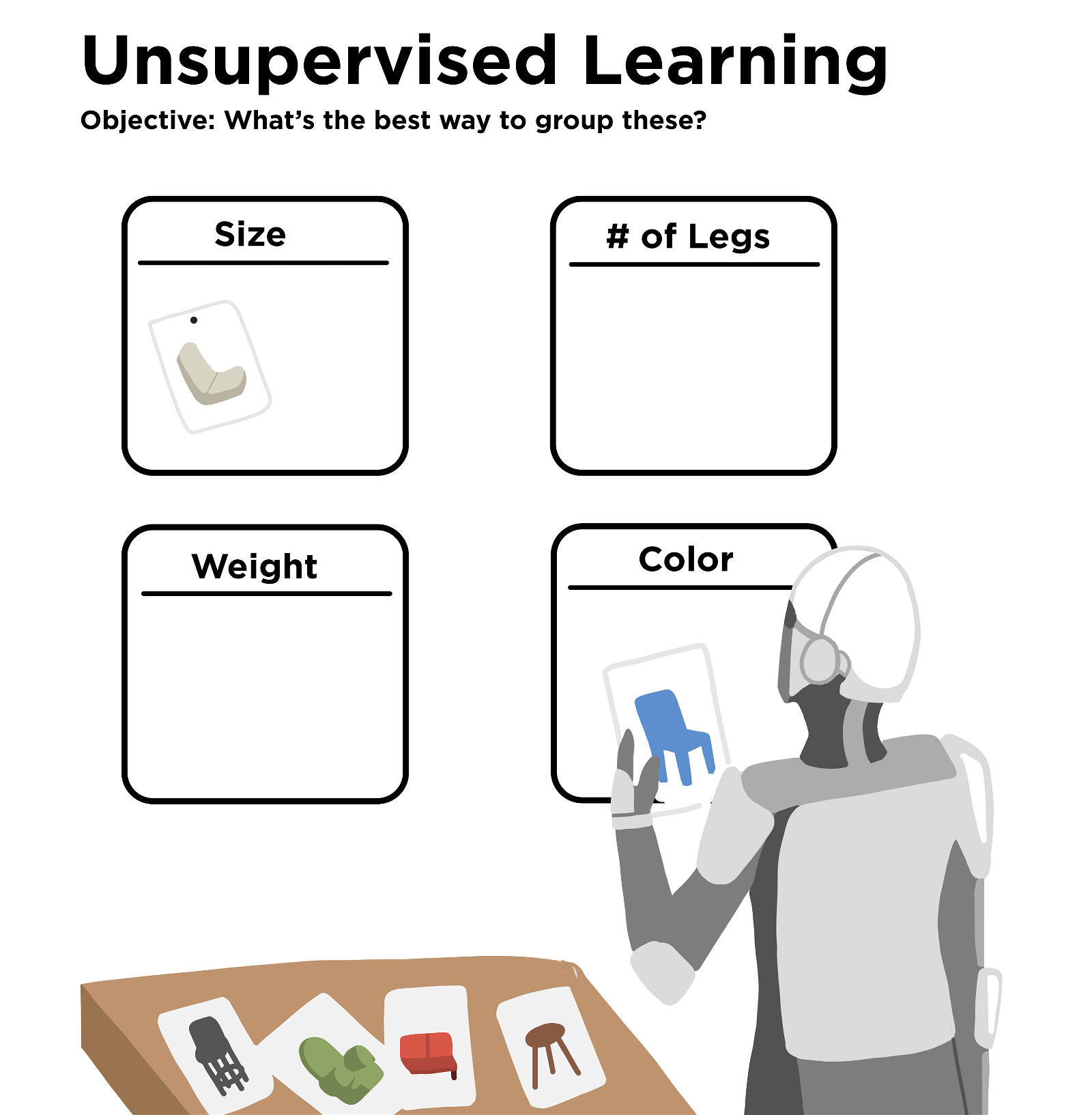
In unsupervised learning, developers don’t give any labels and let the algorithm find its own patterns. Sometimes machine learning algorithms find totally unexpected patterns and solutions. Then researchers can try to learn how the algorithm found its answer. Sometimes this leads to new experiments based on what the algorithm learned.
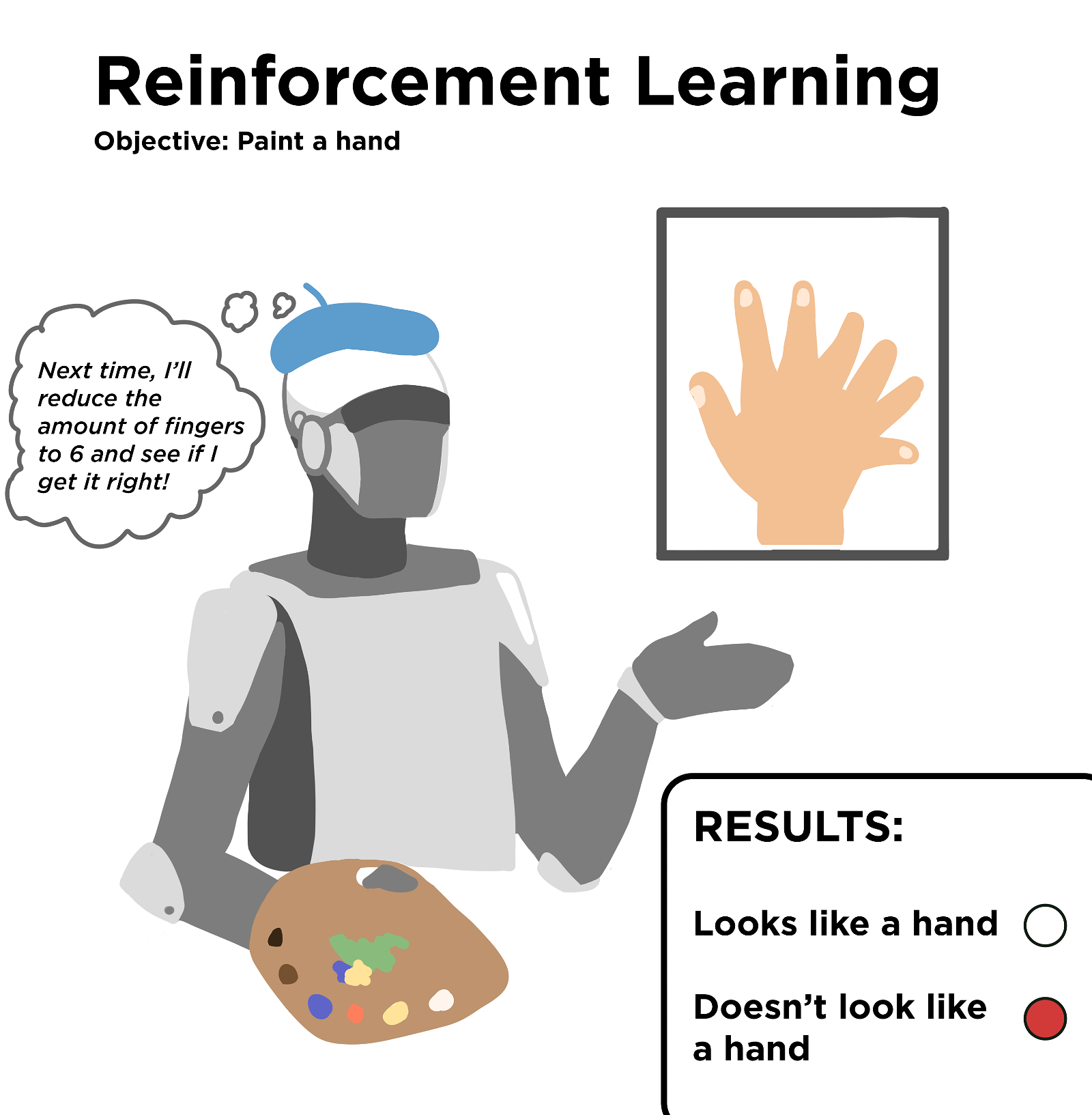
In reinforcement learning, developers give the algorithm a task. This task could be carrying on a natural-sounding conversation or winning a game of chess. As the algorithm tries different approaches, it gets feedback on how well it did. Then it tries another approach to see if it can do better the next time.